Job Scheduling on AWS - Part 1 - Using AWS native services for job scheduling
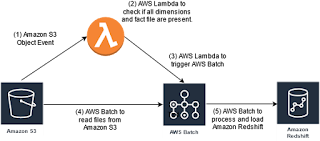
In this blog, I will look at some of the ways to schedule and/or run job/batch-jobs in AWS using AWS native services. In Part 2 of the post, I will talk about how to extend your current on premise job schedule to AWS. 1) Using AWS Lambda – An AWS Lambda can be triggered via several ways. The most common way will be to trigger by a file upload to S3. Create your AWS Lambda function and set the trigger. Your trigger can be a file upload to S3. The moment a file is uploaded it executes the AWS Lambda which contains your execution code. Considerations for using AWS Lam bda – a. When processing large files use AWS Lambda as a trigger rather than a file processor. For example - lets say your requirement is to load fact and dimension files into Amazon Redshift, and you are using A...