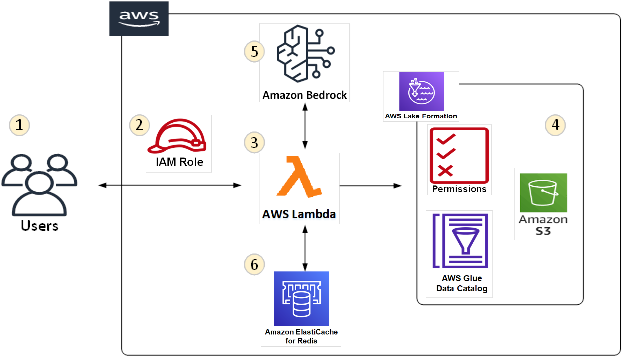
Amazon Bedrock implementation leveraging AWS Lake Formation Tag Based Access Control (LF-TBAC)
While an easy access to pretrained LLM’s revolutionized applications, they have also led us to scenarios which are difficult and complicated. The challenges that LLM’s pose in terms of a safe and secure deployments, can often become the biggest hurdle in LLM implementation. Some of the critical points in a typical LLM deployment are - LLM’s do not differentiate among users; and respond to every question leveraging their training data. Organizations often implement LLM use cases using Retrieval Augmented Generation (RAG) technique which optimizes LLM responses by providing it access to the organization data. Prompt engineering furthers the RAG implementation by ensuring that the LLM responses are limited to the organization data that it has access to. While this “fencing” of LLM responses using RAG and Prompt engineering is useful, it also leads to a scenario where every user now has access to all the data that the LLM has access to. This means all users have access to all data – Pub...